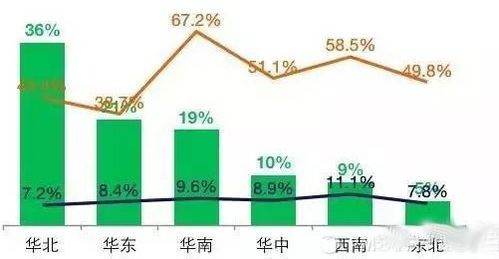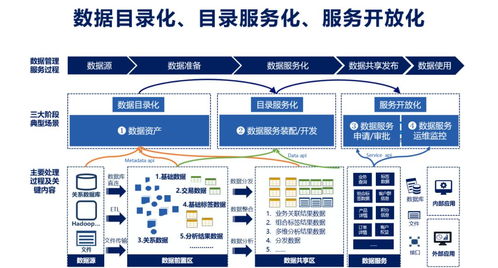
在微服务架构中,数据架构设计是确保系统可扩展性、可靠性和一致性的核心环节,而专门的数据处理服务则是这一架构中的关键组成部分。面试官提出的问题,旨在考察候选人对分布式系统数据管理的深度理解。以下将系统性地阐述微服务数据架构的设计原则,并聚焦于数据处理服务的角色与实现。
一、微服务数据架构的核心原则:去中心化与领域驱动
微服务倡导每个服务拥有其私有的数据库(数据库按服务分配),这实现了数据的去中心化所有权。其核心优势在于:
- 松耦合与独立演进:服务可以独立选择最适合其领域模型的数据存储技术(如SQL、NoSQL),并独立进行 schema 变更和部署。
- 性能与封装:服务直接访问自己的数据,避免了通过笨拙的API进行复杂查询,同时将数据模型细节封装在服务边界内。
这也带来了挑战:数据一致性与跨服务查询。传统的ACID事务难以跨越服务边界,因此数据架构设计必须采用新的模式。
二、数据处理服务的定位与典型模式
数据处理服务并非一个单一服务,而是一类承担特定数据职责的服务集合。它们通常不作为核心业务能力的直接提供者,而是作为支撑系统,确保数据的正确流动、转换和持久化。主要模式包括:
- 数据聚合服务(API组合模式):
- 场景:当用户界面或某个业务服务需要展示来自多个微服务的组合信息时。
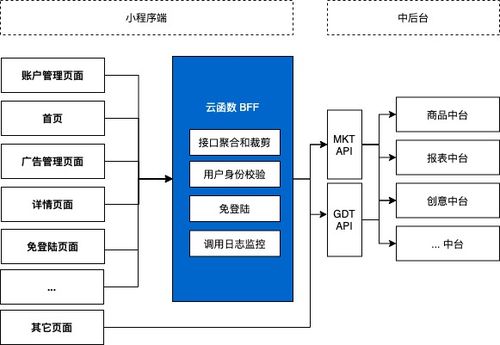
- 设计:创建一个专门的数据聚合服务。该服务通过调用相关微服务的API,获取数据,在内存中进行关联、组合与格式化,然后返回给客户端。它避免了服务间的直接链式调用,降低了耦合和延迟风险。
- 命令查询职责分离(CQRS)中的查询端服务:
- 场景:为了解决复杂查询性能问题,并分离读写负载。
- 设计:将系统的“命令”(写操作)和“查询”(读操作)分离。核心业务服务处理命令,更新其私有数据库。而一个或多个专用的查询服务,维护一个针对读取优化的、非规范化的数据视图(物化视图)。这个视图通过订阅领域事件(如通过事件总线)来异步更新。查询服务只负责高效地提供数据,不包含业务逻辑。
- 事件驱动的数据同步服务(事件溯源与物化视图):
- 场景:维护跨服务的数据一致性或创建用于分析的报告视图。
- 设计:当某个服务完成业务操作后,发布一个“领域事件”(如
OrderConfirmedEvent)。数据处理服务订阅这些事件,根据事件内容更新自己负责的物化视图或向其他系统同步数据。这是实现最终一致性的关键手段。例如,一个“客户订单历史视图服务”可以订阅订单和物流服务的事件,构建完整的客户旅程视图。
- ETL/数据管道服务:
- 场景:面向数据分析、机器学习或数据仓库。
- 设计:这类服务负责从各个微服务的数据库或事件流中抽取数据,进行转换(清洗、聚合),并加载到数据湖、数据仓库或OLAP系统中。它们通常利用如Apache Kafka, Apache Flink, Spark等流/批处理框架构建。
三、关键设计考量与技术选型
- 一致性模型:明确业务对一致性的要求。CAP定理下,跨服务操作通常选择最终一致性。通过Saga模式(一系列补偿性事务)来管理跨服务的业务事务,通过事件驱动实现数据同步。
- 数据流技术:事件总线(如RabbitMQ、Apache Kafka)是数据处理服务的“脊柱”。Kafka因其高吞吐、持久化和流处理能力,成为实现事件溯源、CQRS视图更新和流式ETL的首选。
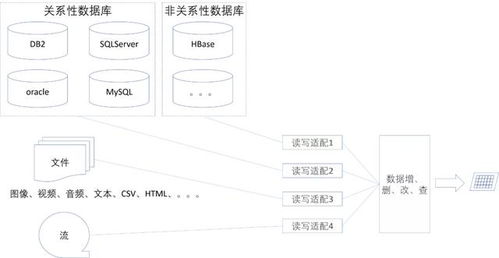
- 存储技术多元化:
- 核心业务服务:根据领域特点选用PostgreSQL(关系型)、MongoDB(文档型)等。
- 查询/视图服务:可能使用Elasticsearch(全文搜索)、Redis(缓存热视图)、Cassandra(时间序列)等,专为查询优化。
- 缓存策略:在数据处理服务中广泛使用缓存以提升性能。例如,聚合服务可以缓存组合后的API响应;查询服务可以缓存物化视图的常用查询结果。需制定清晰的缓存失效策略(通常基于事件触发)。
- 可观察性与数据血缘:由于数据在多个服务间流动,必须建立强大的监控,包括事件流的延迟、物化视图的更新滞后时间。记录数据血缘对于问题排查和合规性至关重要。
四、
在微服务数据架构中,数据处理服务扮演着粘合剂和加速器的角色。它们通过异步、事件驱动的方式,将各自为政的数据孤岛连接起来,既维护了服务的自治性,又满足了全局的数据需求。成功的设计始于清晰的领域边界划分,核心在于拥抱最终一致性并熟练运用事件驱动架构,最终通过多样化的存储与流处理技术落地。理解这些模式,并能在业务场景中权衡选择,是设计出健壮、可扩展的微服务系统的关键。